





记录一个独立开发者从零到一构建监控系统的技术历程
第一阶段:技术选型的纠结
为什么选 Go + Vue?
后端选 Go 几乎没有犹豫。监控系统对性能和并发有天然要求,Go 的 goroutine 模型简直是为这种场景量身定做的。而且单二进制部署太香了,不用折腾 JVM、不用装 Python 环境。
前端纠结了一下 React 还是 Vue。最后选了 Vue 3,主要是 Composition API 比较舒服,加上 Vite 的体验太丝滑了。
技术栈最终定型:
├── 后端: Go + Gin + gRPC
├── 前端: Vue 3 + TypeScript + Vite
├── 数据库: PostgreSQL + Redis
└── 探针: Go (跨平台编译)探针通信:HTTP 还是 gRPC?
这个问题困扰了我很久。
最开始用的 HTTP 轮询,简单粗暴。但问题很快暴露:
轮询间隔太长,实时性差
轮询间隔太短,服务器压力大
服务端无法主动推送指令给探针
后来改成了 gRPC 双向流。探针和服务端建立一条长连接,数据可以双向流动:
// 探针端:建立双向流连接
stream, err := c.client.Connect(ctx)
// 发送数据
stream.Send(&pb.AgentMessage{...})
// 接收服务端指令
msg, err := stream.Recv()这样服务端可以随时推送更新指令、配置变更给探针,探针也能实时上报数据。
第二阶段:增量上报——带宽优化的艺术
问题:全量上报太浪费
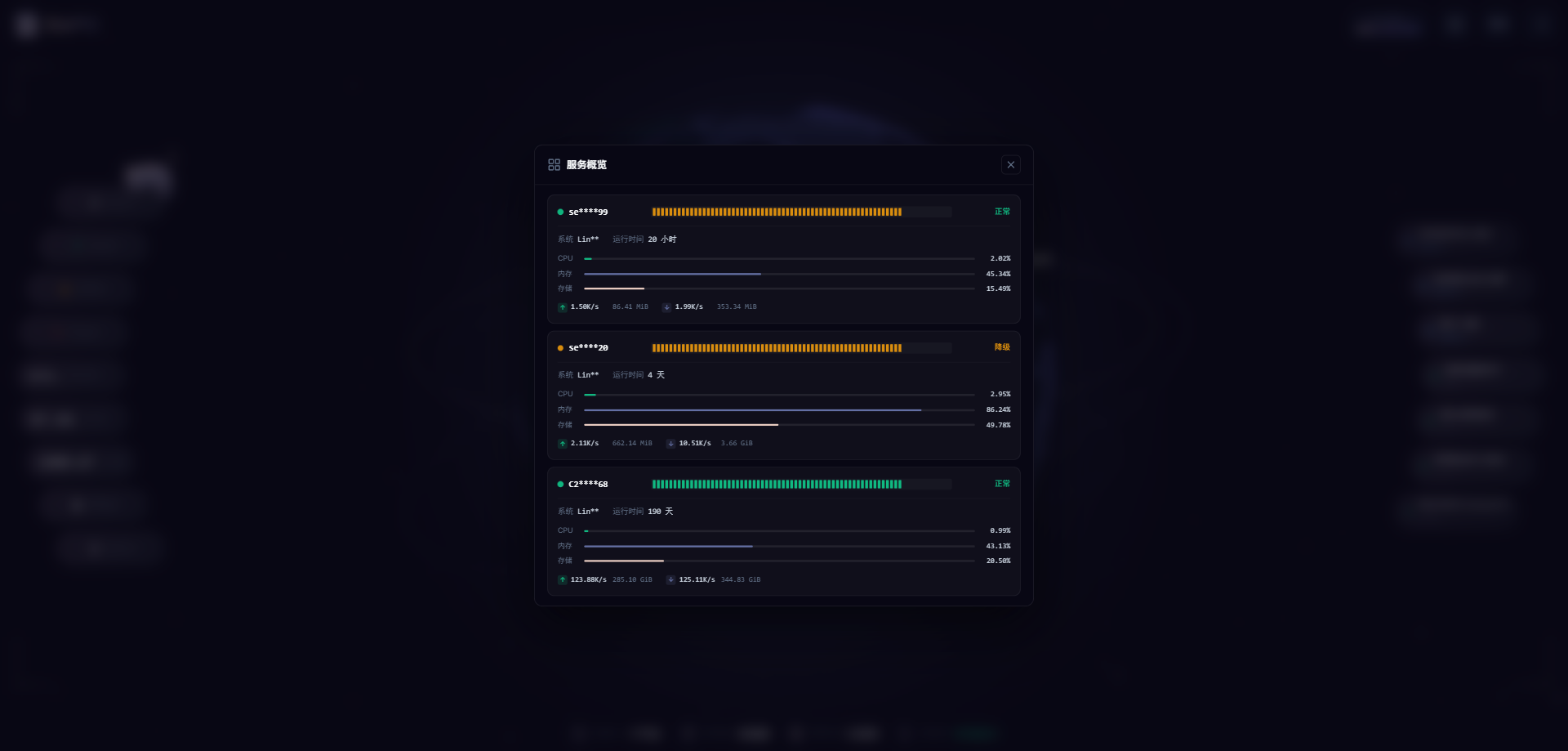
探针每秒采集一次数据,每次上报的 SystemMetrics 结构体大概 5-10KB。如果有 100 个节点,每秒就是 500KB-1MB 的流量。
但仔细想想,大部分时候服务器状态是稳定的。CPU 从 30% 变成 31%,有必要上报吗?
解决方案:边缘计算 + 增量上报
我在探针端实现了一个 DeltaReporter,只有当指标变化超过阈值时才上报:
// probe/edge/delta.go
type DeltaConfig struct {
CPUThreshold float64 // CPU 变化超过 2% 才上报
MemThreshold float64 // 内存变化超过 1% 才上报
DiskThreshold float64 // 磁盘变化超过 0.5% 才上报
NetworkThreshold float64 // 网络速率变化超过 10% 才上报
ForceFullEvery int // 每 60 次强制全量上报
}核心逻辑是对比当前指标和上次上报的指标,只发送变化的字段:
func (d DeltaReporter) ComputeDelta(current SystemMetrics) *DeltaResult {
// 首次上报或强制全量
if d.lastMetrics == nil || d.counter >= d.config.ForceFullEvery {
d.lastMetrics = current
return &DeltaResult{Metrics: current, IsDelta: false}
}
// 计算增量
delta := &SystemMetrics{Timestamp: current.Timestamp}
// CPU 变化检测
if d.hasSignificantChange(d.lastMetrics.CPU.UsagePercent,
current.CPU.UsagePercent,
d.config.CPUThreshold) {
delta.CPU = current.CPU
hasChanges = true
}
// ... 其他字段类似
}服务端合并:MetricsMerger
增量数据到了服务端,需要和缓存的完整数据合并:
// server/grpc/merger.go
func (m MetricsMerger) Merge(nodeID string, delta pb.SystemMetrics) MergeResult {
if !delta.IsDelta {
m.cache[nodeID] = delta
return MergeResult{Metrics: delta}
}
cached := m.cache[nodeID]
merged := m.mergeMetrics(cached, delta)
m.cache[nodeID] = merged
return MergeResult{Metrics: merged}
}效果:带宽节省了 60-80%,而且对实时性几乎没有影响。
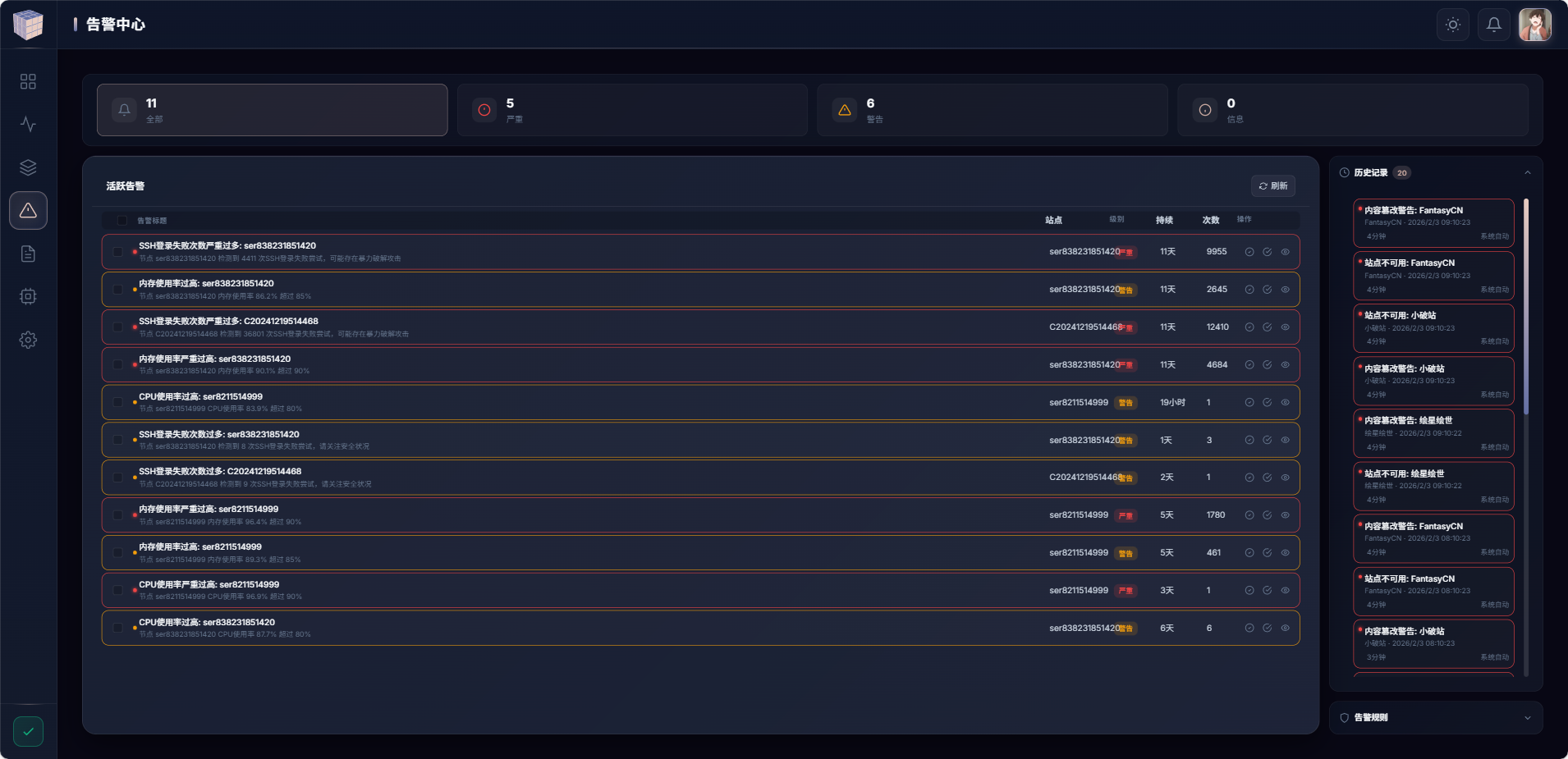
第三阶段:探针激活机制
问题:如何安全地管理探针?
探针部署在用户的服务器上,如何确保:
只有授权的探针才能上报数据
探针被盗用后可以快速撤销
部署过程尽量简单
解决方案:激活码 + Token 双重认证
第一步:生成激活码
探针首次启动时,生成一个 6 位激活码(排除了容易混淆的字符):
// probe/activation/activation.go
func generateActivationCode() string {
const charset = "ABCDEFGHJKLMNPQRSTUVWXYZ23456789" // 排除 0OIL1
code := make([]byte, 6)
randomBytes := make([]byte, 6)
rand.Read(randomBytes)
for i := 0; i < 6; i++ {
code[i] = charset[int(randomBytes[i])%len(charset)]
}
return string(code)
}第二步:管理后台激活
用户在后台输入激活码,服务端下发 Token:
case *pb.ServerMessage_Activation:
if payload.Activation.Success {
c.SetToken(payload.Activation.Token)
activation.Activate(payload.Activation.Token)
}第三步:HMAC 签名验证
每次上报数据都带上签名,防止伪造:
func (c Client) signMessage(msg pb.AgentMessage) {
data := msg.NodeId + strconv.FormatInt(msg.Timestamp, 10)
mac := hmac.New(sha256.New, []byte(c.token))
mac.Write([]byte(data))
msg.Signature = hex.EncodeToString(mac.Sum(nil))
}第四阶段:探针自动更新
问题:如何远程更新探针?
探针部署在用户服务器上,总不能每次更新都让用户手动下载吧。
解决方案:服务端推送 + 签名验证
服务端推送更新指令:
// 通过 gRPC 流推送
stream.Send(&pb.ServerMessage{
Payload: &pb.ServerMessage_Update{
Update: &pb.UpdateCommand{
Version: "1.2.0",
DownloadURL: "https://xxx/probe_linux_amd64",
Checksum: "sha256:...",
Signature: "ed25519:...",
},
},
})探针端处理更新:
func (u Updater) DownloadAndUpdate(info UpdateInfo) error {
// 1. 下载新版本
u.downloadFile(info.DownloadURL, downloadPath)
// 2. 校验 SHA256
checksum := calculateSHA256(downloadPath)
if checksum != info.Checksum {
return fmt.Errorf("checksum mismatch")
}
// 3. 验证 Ed25519 签名
if err := signing.VerifyFile(downloadPath, info.Signature); err != nil {
return fmt.Errorf("signature verification failed")
}
// 4. 替换并重启
u.applyUpdate(oldPath, downloadPath)
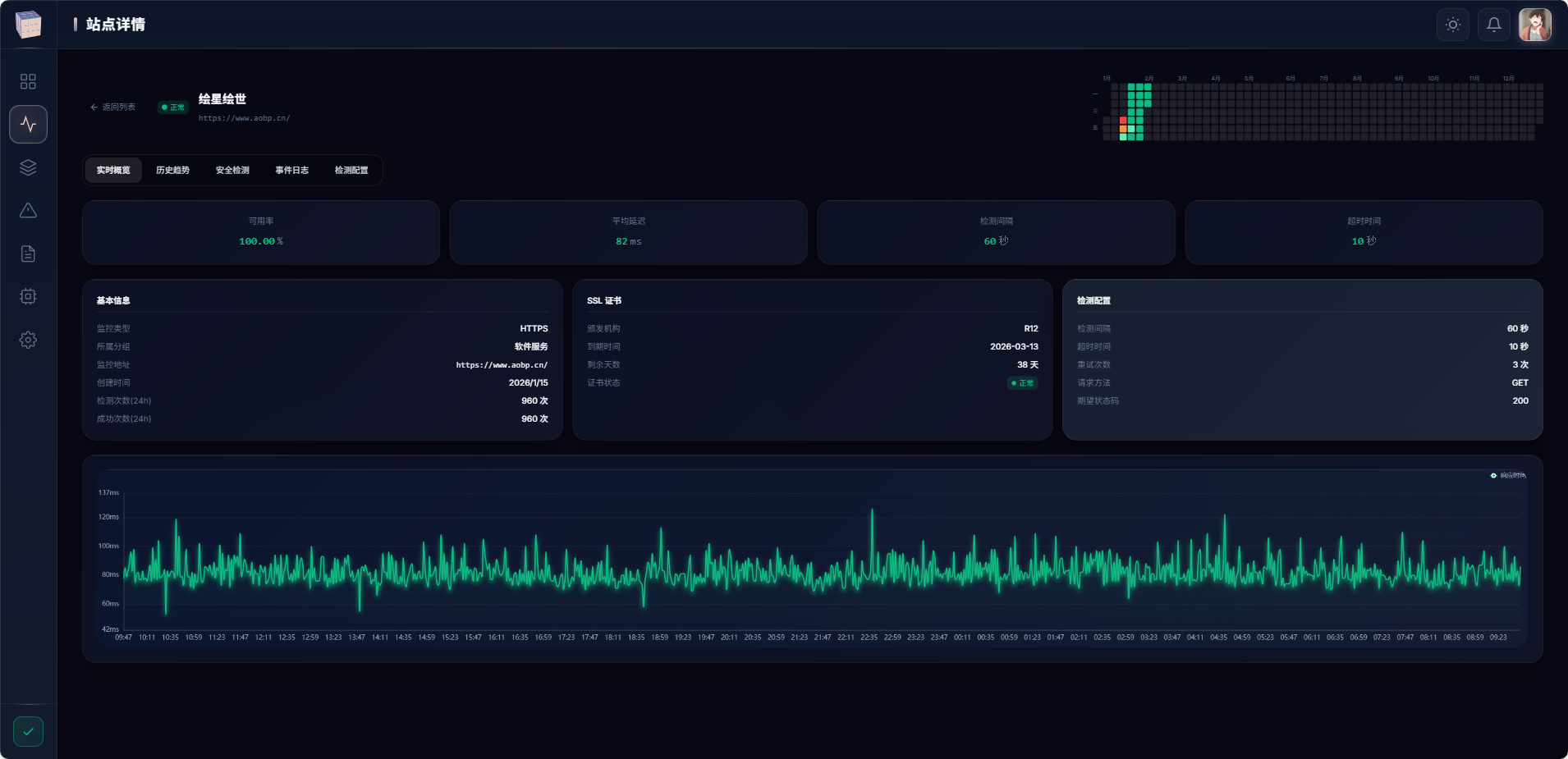
}第五阶段:实时推送——WebSocket Hub
问题:前端如何实时展示数据?
探针数据通过 gRPC 到达服务端,但前端是 HTTP/WebSocket。需要一个桥梁。
解决方案:BrowserHub
// server/websocket/browser_hub.go
type BrowserHub struct {
clients map[*BrowserClient]bool
siteSubscribers map[uint]map[*BrowserClient]bool // 订阅特定站点
nodeSubscribers map[string]map[*BrowserClient]bool // 订阅特定节点
allSubscribers map[*BrowserClient]bool // 订阅所有
}前端可以选择订阅模式:
// 订阅所有更新
ws.send(JSON.stringify({ type: 'subscribe_all' }))
// 只订阅某个站点
ws.send(JSON.stringify({ type: 'subscribe_site', site_id: 123 }))
```
服务端收到探针数据后,广播给订阅的客户端:
```go
func (h *BrowserHub) BroadcastNodeMetrics(nodeID string, metrics interface{}) {
msg := BrowserMessage{Type: "node_metrics", NodeID: nodeID, Payload: metrics}
h.broadcastToNodeSubscribers(nodeID, msg)
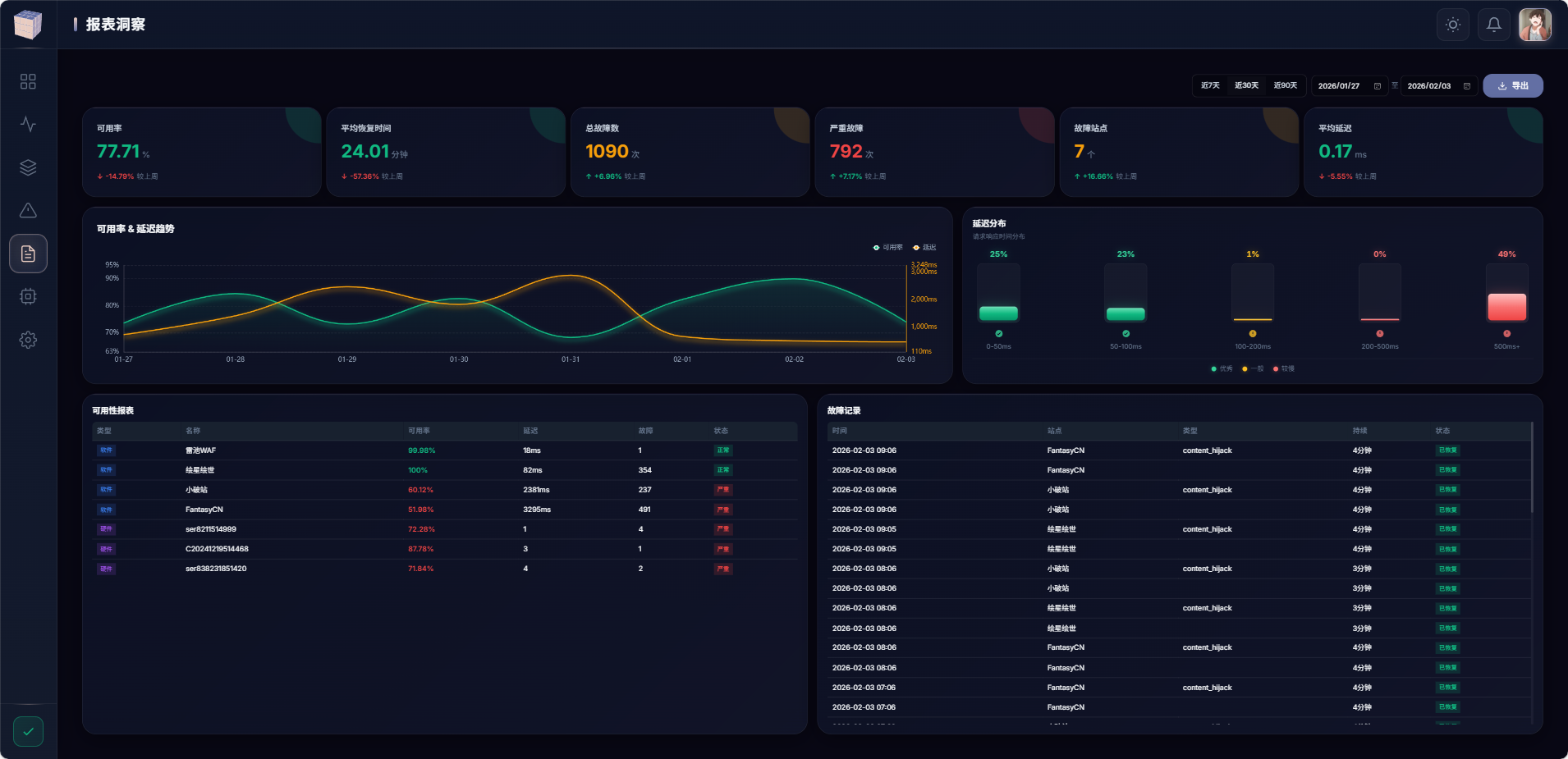
}第六阶段:数据清理——别让数据库爆炸
问题:监控数据增长太快
每个站点每 30 秒检测一次,每个节点每秒上报一次。一个月下来,数据量惊人。
解决方案:可配置的数据清理器
// server/cleaner/cleaner.go
type CleanerConfig struct {
NodeMetricsRetentionDays int // 节点指标保留 7 天
SiteChecksRetentionDays int // 站点检测保留 30 天
NotificationLogsRetentionDays int // 通知日志保留 30 天
ResolvedAlertsRetentionDays int // 已解决告警保留 90 天
CleanupInterval time.Duration // 每小时清理一次
}清理逻辑很简单,但有个细节:启动后延迟 5 分钟再执行首次清理,避免启动时负载过高。
func (c *Cleaner) Start() {
go func() {
// 启动后延迟 5 分钟
select {
case <-time.After(5 * time.Minute):
c.RunCleanup()
case <-c.stopChan:
return
}
// 定时执行
ticker := time.NewTicker(c.config.CleanupInterval)
for {
select {
case <-ticker.C:
c.RunCleanup()
case <-c.stopChan:
return
}
}
}()
}一些有意思的小细节
gRPC 错误信息翻译
gRPC 的错误信息对用户不友好,比如 error reading from server: EOF。我写了个翻译函数:
func translateGRPCError(err error) string {
translations := []struct {
pattern string
message string
}{
{"error reading from server: EOF", "服务器关闭了连接"},
{"connection refused", "服务器拒绝连接(服务可能未启动)"},
{"context deadline exceeded", "连接超时(服务器无响应)"},
// ...
}
for _, t := range translations {
if contains(errStr, t.pattern) {
return t.message
}
}
return errStr
}指数退避重连
网络断开后不能疯狂重连,要用指数退避:
// 1s -> 2s -> 4s -> 8s -> ... -> 60s (最大)
currentInterval = time.Duration(float64(currentInterval) * 2.0)
if currentInterval > 60 * time.Second {
currentInterval = 60 * time.Second
}探针退出交互
前台运行的探针按 Ctrl+C 时,不是直接退出,而是弹出选择菜单:
检测到退出信号,请选择操作:
[1] 安装为后台服务并退出
[2] 停止探针
[3] 继续前台运行
这个小细节让部署体验好了很多。
后记
如果你也在做类似的项目,希望这篇文章能给你一些参考。
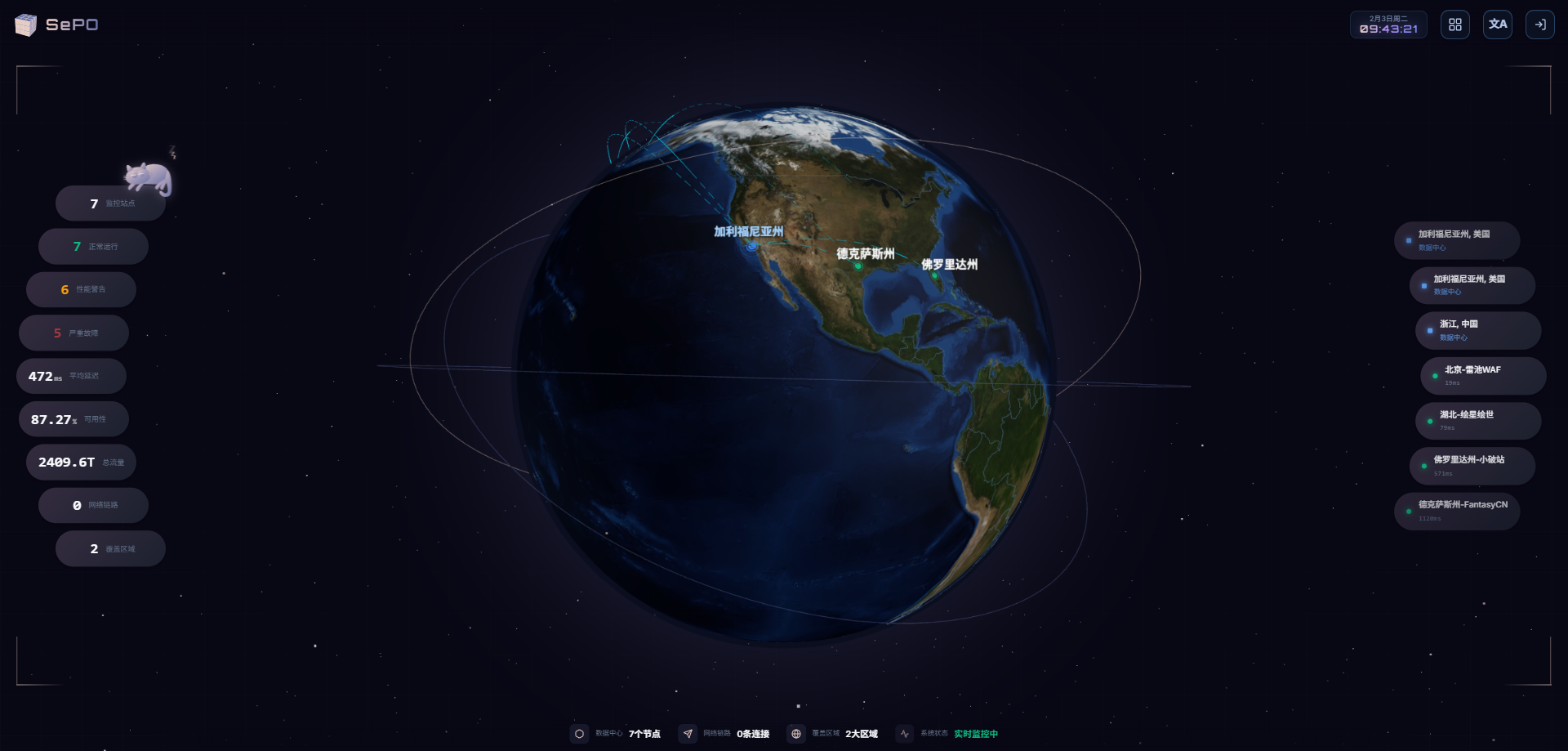
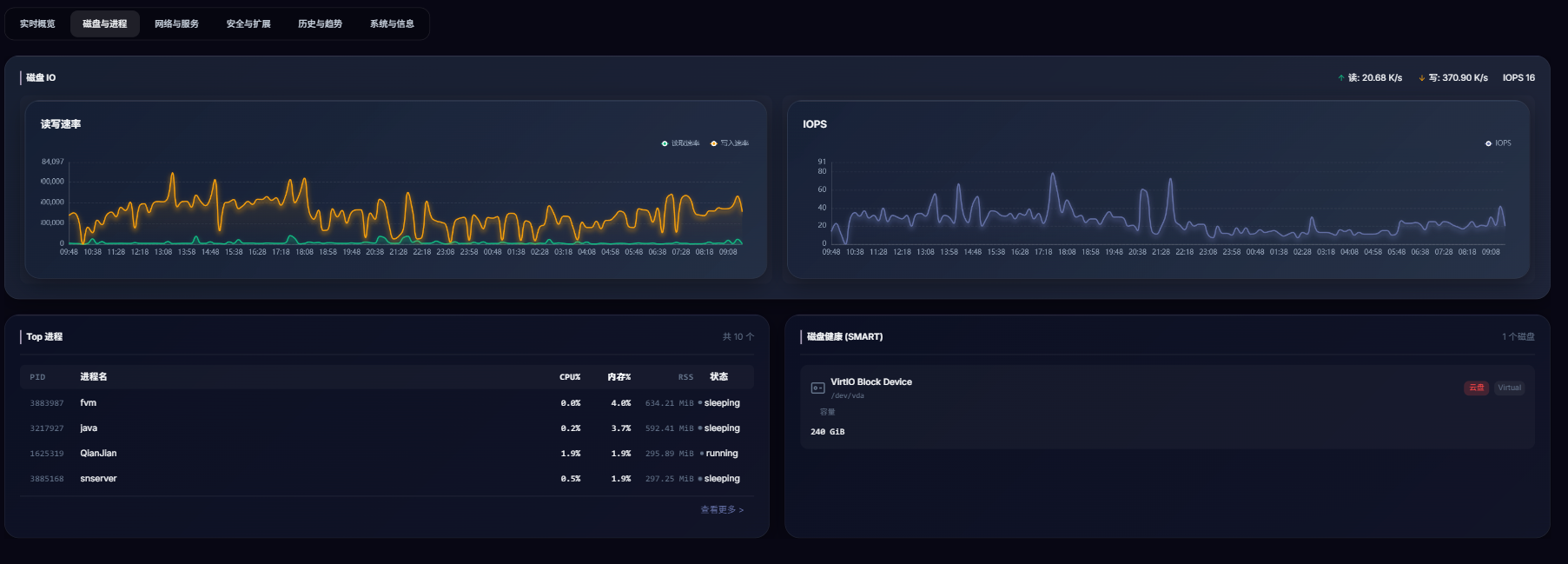
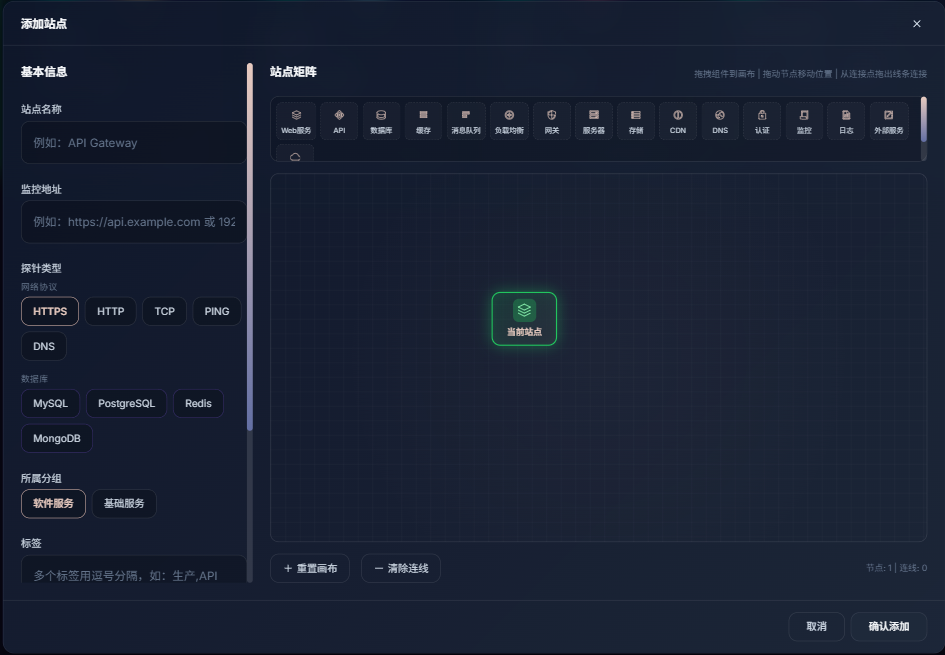
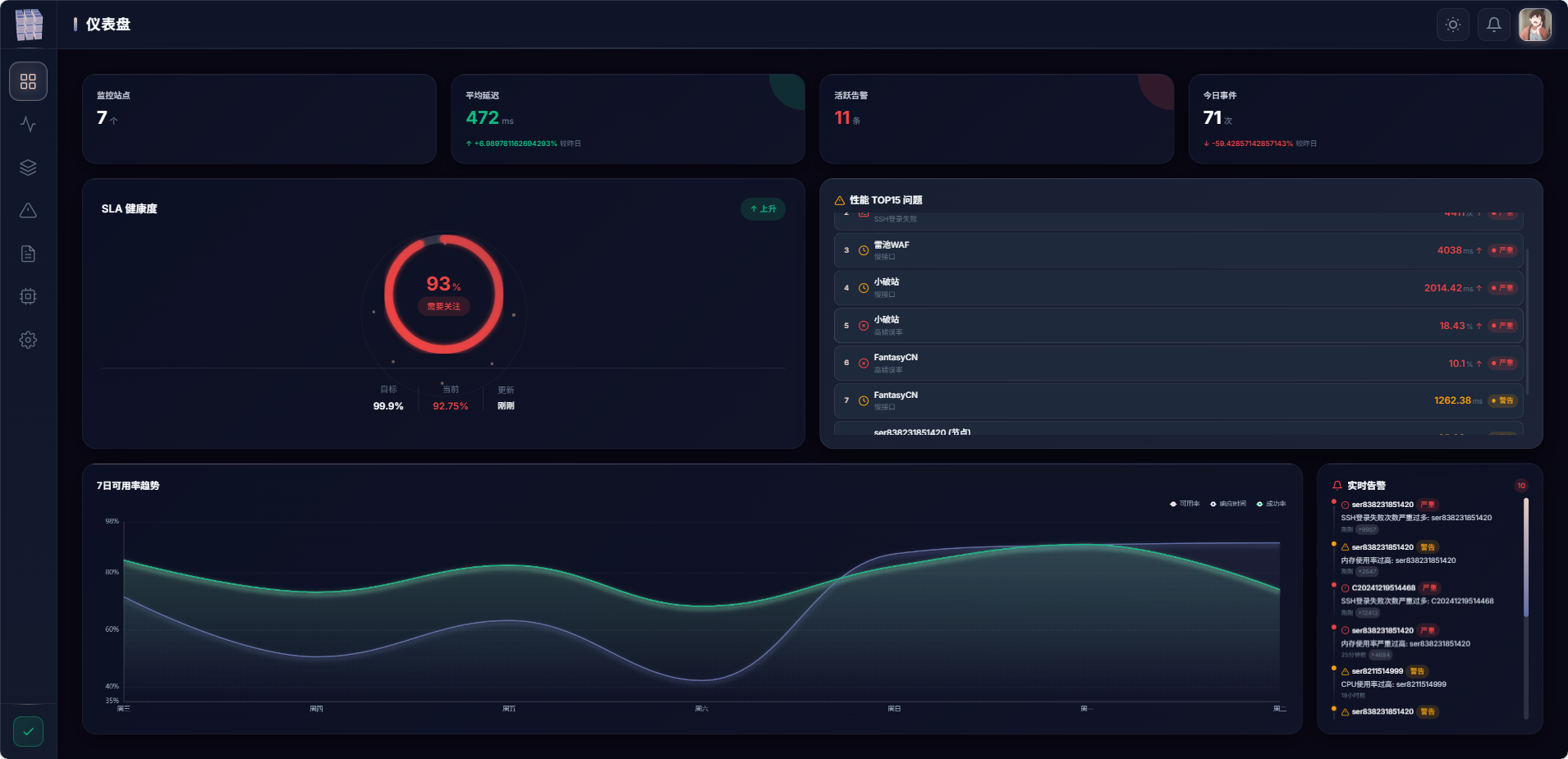
DeePulse 开发手记:一个全栈监控平台的诞生
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。

赞赏支持
如果觉得文章对你有帮助,可以请作者喝杯咖啡 ☕
评论交流
欢迎留下你的想法